Informática Aplicada a la Gestión Pública. Facultad Derecho UMU
Capítulo 4. Bases de datos. Introducción.
![]()
4.1 Definición y Características de un SBD
4.2 Recursos que componen un SBD
4.3 Distintos Niveles de un SBD
4.4 Modelos de datos
4.5 Programas que conforman el DBMS
4.6 Personas relacionadas con un SBD
4.7 Otros tipos de bases de datos
4.1.- Definición y Características de un SBD
Desde tiempos inmemoriales, los datos han sido almacenados por los humanos en algún tipo de soporte (piedra, papel, madera, etc.) a fin de que quedara constancia. Así mismo estos datos han de ser interpretados para que se conviertan en información útil, interpretación que supone un fenómeno de agrupación y clasificación.En los años 40 del siglo pasado, los sistemas de archivos generados a través de los primeros lenguajes de programación como Cobol y Fortran, permitieron almacenar los datos a través de archivos sin formato alguno (texto plano) con las únicas funciones de lectura y escritura.
Posteriormente surgió el denominado sistema de ficheros que es un conjunto de programas que prestan servicio a los usuarios finales. Cada programa define y maneja sus propios datos. Los sistemas de ficheros surgieron al tratar de informatizar el manejo de los archivadores manuales con objeto de proporcionar un acceso más eficiente a los datos. En lugar de establecer un sistema centralizado en donde almacenar todos los datos de la organización o empresa, se escogió un modelo descentralizado en el que cada división o departamento almacena y gestiona sus propios datos.
Los sistemas de ficheros presentan una serie de inconvenientes:
* Separación y aislamiento de los datos. Cuando los datos se separan en diferentes ficheros, es más complicado acceder a ellos, ya que el programador de aplicaciones debe sincronizar el procesamiento de los distintos ficheros implicados para asegurar que se extraen los datos correctos.
* Duplicación de datos. La redundancia de datos existente en los sistemas de ficheros hace que se desperdicie espacio de almacenamiento y lo que es más importante, puede llevar a que se pierda la consistencia de los datos. Se produce una inconsistencia cuando copias de los mismos datos no coinciden.
* Dependencia de datos. Ya que la estructura física de los datos (la definición de los ficheros y de los registros) se encuentra codificada en los programas de aplicación, cualquier cambio en dicha estructura es difícil de realizar. El programador debe identificar todos los programas afectados por este cambio, modificarlos y volverlos a probar, lo que cuesta mucho tiempo y está sujeto a que se produzcan errores. A este problema, tan característico de los sistemas de ficheros, se le denomina también falta de independencia de datos lógica-física.
* Formatos de ficheros incompatibles. Ya que la estructura de los ficheros se define en los programas de aplicación, es completamente dependiente del lenguaje de programación. La incompatibilidad entre ficheros generados por distintos lenguajes hace que los ficheros sean difíciles de procesar de modo conjunto.
* Consultas fijas y proliferación de programas de aplicación. Desde el punto de vista de los usuarios finales, los sistemas de ficheros fueron un gran avance comparados a los sistemas manuales. Como consecuencia de esto, creció la necesidad de realizar distintos tipos de consultas de datos, sin embargo, los sistemas de ficheros son muy dependientes del programador de aplicaciones: cualquier consulta o informe que se quiera realizar debe ser programado por él. En algunas organizaciones se conformaron con fijar el tipo de consultas e informes, siendo imposible realizar otro tipo de consultas que no se hubieran tenido en cuenta a la hora de escribir los programas de aplicación.
Los inconvenientes de los sistemas de ficheros se pueden atribuir a dos factores:
-
* La definición de los datos se encuentra codificada dentro de los programas de aplicación, en lugar de estar almacenada aparte y de forma independiente.
* No hay control sobre el acceso y la manipulación de los datos más allá de lo impuesto por los programas de aplicación.
Los sistemas de bases de datos tienen su origen en el proyecto estadounidense Apolo de mandar al hombre a la luna, gran cantidad de información que requería el proyecto. La primera empresa encargada del proyecto, NAA ("North American Aviation"), desarrolló un software denominado GUAM ("General Update Access Method") que estaba basado en el concepto de que varias piezas pequeñas se unen para formar una pieza más grande, y así sucesivamente hasta que el producto final está ensamblado.
El primer sistema gestor de bases de datos comercial, IDS ("Integrated Data Store"), se diseñó bajo el concepto de modelo de datos en red (Bachgman, 1965). Posteriormente se desarrolló el IMS ("Information Management System"), sobre el concepto del modelo de datos jerárquico. A estos sistemas se accedía normalmente mediante lenguajes de programación como COBOL usando interfaces de bajo nivel, lo cual implicaba que las tareas de creación de aplicaciones y mantenimiento de los datos fuesen controlables, aunque bastante complejas.
Actualmente con el auge de los medios informáticos aparece el almacenamiento en soporte magnético bajo forma de discos, ofreciendo mayores posibilidades de almacenaje, ocupando menos espacio y ahorrando un tiempo considerable en la búsqueda y tratamiento de los datos. Así se populariza el concepto de base de datos y con ellas las diferentes metodologías de diseño y tratamiento.
El objetivo básico de cualquier base de datos es el almacenamiento de símbolos, números y letras carentes de un significado en sí, que mediante un tratamiento adecuado se convierten en información útil. Un ejemplo podría ser el siguiente dato: 20001224, con el tratamiento correcto podría convertirse en la siguiente información: "Fecha de nacimiento: 24 de diciembre del año 2000".
Según van evolucionando en el tiempo, las necesidades de almacenamiento de datos van creciendo y con ellas las necesidades de transformar los mismos datos en información de muy diversa naturaleza. Esta información es utilizada como herramientas de trabajo y soporte para la toma de decisiones por un gran colectivo de profesionales que consideran dicha información como base de su actividad. Por este motivo el trabajo del diseñador de bases de datos es cada vez más delicado, un error en el diseño o en la interpretación de datos puede dar lugar a información incorrecta y conducir al usuario a la toma de decisiones equivocadas. Se hace necesario la creación de un sistema que ayude al diseñador a crear estructuras correctas y fiables, minimizando los tiempos de diseño y explotando todos los datos, así nació la metodología de diseño de bases de datos.
Se puede definir una base de datos, como un fichero en el cual se almacena información de cualquier tipo. En dicho fichero la información se guarda en campos o delimitadores, por ejemplo, podemos almacenar el nombre y apellidos de las personas de modo separado, de ésta forma es posible obtener del fichero todos los nombres o todos los apellidos, tanto de forma separada como conjunta. Normalmente el número de campos que se tienen en una base varía según las necesidades en cuanto a gestión de datos, de forma que después se pueda explotar la información de forma ordenada y separada, aunque el resto de la información sigue almacenada y guardada en la base de datos
Una base de datos, no es sólo el fichero en donde están datos, sino que en dicho arvhivo se encuentra la estructura de los datos, así que para saber qué longitud tiene cada campo,hay que conocer como se llama el campo y qué longitud en caracteres tiene, así como el tipo de datos en dicho campo, porque puede contener desde letras a números o incluso otros datos más complejos, dependiendo de la estructura de la base y del sistema gestor.
En realidad aparte de los datos que son almacenados en el archivo, también hay una serie de datos, en los que se informa del tipo de campo, los campos y la longitud de cada campo, es lo que se llama gestor de datos, que permite saber que cada registro (un registro es una suma de campos, por ejemplo a Marisol Collazos, Marisol lo guardamos en el campo Nombre y Collazos en el campo Apellidos, cada registro es cada persona que almacenamos en la base, osea una persona es un registro y cada regitro está constituido por los campos Nombre y Apellido
Un Sistema de Bases de Datos (SBD) es una serie de recursos para manejar grandes volúmenes de información, sin embargo no todos los sistemas que manejan información son bases de datos.
Un sistema de bases de datos debe responder a las siguientes características:
- Abstracción de la información. Ahorran a los usuarios detalles acerca del almacenamiento físico de los datos. Da lo mismo si una base de datos ocupa uno o cientos de archivos, este hecho se hace transparente al usuario. Así, se definen varios niveles de abstracción.
- Independencia de los Datos. Es decir, que los datos nunca dependen del programa y por tanto cualquier aplicación pueda hacer uso de éllos.
- Reducción de la Redundancia.Rdundancia es la existencia de duplicación de los datos, al reducir ésta al máximo conseguimos un mejor aprovechamiento del espacio y además evitamos que existan inconsistencias entre los datos. Las inconsistencias se dan cuando nos encontramos con datos contradictorios.
- Seguridad. Un SGBD debe permitir que tengamos un control sobre la seguridad de los datos, frente a usuarios malintencionados que intenten leer información no permitida; frente a ataques que deseen manipular o destruir la información; o simplemente ante las torpezas de algún usuario autorizado.
- Integridad. Se trata de adoptar las medidas necesarias para garantizar la validez de los datos almacenados. Se trata de proteger los datos ante fallos de hardware, datos introducidos por usuarios descuidados, o cualquier otra circunstancia capaz de corromper la información almacenada. Los SGBD proveen mecanismos para garantizar la recuperación de la base de datos hasta un estado consistente conocido en forma automática.
- Respaldo. Los SGBD deben proporcionar una forma eficiente de realizar copias de seguridad de la información almacenada en ellos, y de restaurar a partir de estas copias los datos que se hayan podido perder.
- Control de la concurrencia. En la mayoría de entornos (excepto quizás el personal), lo más habitual es que sean muchas las personas que acceden a una base de datos, bien para recuperar información, bien para almacenarla. Y es también frecuente que dichos accesos se realicen de forma simultánea. Así pues, un SGBD debe controlar este acceso concurrente a la información, que podría derivar en inconsistencias.
- Manejo de transacciones. Una transacción es un programa que se ejecuta como una sola operación. Esto quiere decir que el estado luego de una ejecución en la que se produce un fallo es el mismo que se obtendría si el programa no se hubiera ejecutado. Los SGBD proveen mecanismos para programar las modificaciones de los datos de una forma mucho más simple que si no se dispusiera de ellos.
- Tiempo de respuesta. Lógicamente, es deseable minimizar el tiempo que el SGBD tarda en darnos la información solicitada y en almacenar los cambios realizados.

- El expresidente del Real Madrid C.F. sancionado con multa de 360000 euros por vulnerar la Ley Orgánica de Protección de Datos
- El Opus Dei sancionado a pagar 60101 euros.
- Multa de 6000 euros por compartir en el Emule una base de datos
- Sanción de 1000 euros por el envío de un único e-mail con información comercial
- Multa de 600 euros por dejar a la vista 42 direcciones de e-mail
- Las empresas de telecomunicaciones y los bancos, los que más vulneran los datos de los ciudadanos
4.2.- Recursos que componen un SBD
Un SBD está formado por:- Personas
- Máquinas
- Programas
Son los encargados de manejar los datos, son conocidos como DBMS ("Data Base Management System") o también SGBD (Sistema Gestor de Base de Datos). Los DBMS tienen dos funciones principales que son:
- La definición de las estructuras para almacenar los datos.
- La manipulación de los datos.
- Datos
Es lo que se conoce como base de datos propiamente dicha. Para manejar estos datos utilizamos una serie de programas.
4.3.- Distintos Niveles de un SBD
Los SBD pueden ser estudiados desde tres niveles distintos:-
1 Nivel interno o físico
Es el nivel real de los datos almacenados, considerado como el nivel inferior de abstracción, es decir cómo se almacenan los datos, ya sea en registros, o de otra forma. Este nivel es usado por muy pocas personas que deben estar cualificadas para ello, lleva asociada una representación de los datos, que es lo que denominamos Esquema Físico.
2 Nivel conceptual
Es el correspondiente a una visión de la base de datos desde el punto de vista del mundo real. Es decir, tratamos con la entidad u objeto representado, sin importarnos como está representado o almacenado. Este nivel lleva asociado el Esquema Conceptual.
3 Nivel externo o visión
Son partes del esquema conceptual. El nivel conceptual presenta toda la base de datos, mientras que los usuarios por lo general sólo tienen acceso a pequeñas parcelas de ésta. El nivel visión es el encargado de dividir estas parcelas. Un ejemplo sería el caso del empleado que no tiene porqué tener acceso al sueldo de sus compañeros. El esquema asociado a éste nivel es el Esquema de Visión.
A menudo el nivel físico no es facilitado por muchos DBMS, esto es, no permiten al usuario elegir como se almacenan sus datos y vienen con una forma estándar de almacenamiento y manipulación de los datos.
La arquitectura a tres niveles se puede representar como sigue:

4.4.- Modelos de datos
Un modelo de datos para las bases de datos es un conjunto de conceptos que se usan para describir la estructura de una base de datos. Esa colección de conceptos incluyen entidades, atributos y relaciones. La mayoría de los modelos de datos poseen un conjunto de operaciones básicas para especificar consultas y actualizaciones de la base de datos.Para representar el mundo real a través de esquemas conceptuales se han creado una serie de modelos:

- Modelo Relacional de Datos
- Modelo de Red
- Modelo Jerárquico
- Modelo Orientado a Objetos
4.1 Modelo Relacional de Datos
Se representa el mundo real mediante tablas relacionadas entre sí por columnas comunes. Ej.:
| Num. empleado | Nombre | Sección |
| 33 | Pepe | 25 |
| 34 | Juan | 25 |
| Sección | Nombre |
| 25 | Textil |
| 26 | Pintura |
4.2 Modelo de Red
Representamos al mundo real como registros lógicos que representan a una entidad y que se relacionan entre sí por medio de flechas. Ej.:

Tiene forma de árbol invertido. Un padre puede tener varios hijos pero cada hijo sólo puede tener un padre. Ej.:


El modelo jerárquico sólo admite relaciones 1:1 ó 1:N.
En caso de que tuviésemos la necesidad de otro tipo de asociaciones y queramos usar el esquema jerárquico, recurriríamos a una duplicación de la información en el esquema, pero sólo a nivel esquemático.
Ej.: Tenemos dos entidades (cliente y cuenta), queremos que un cliente pueda poseer varias cuentas, y que una cuenta pueda tener como titulares a varios clientes. Usando el modelo jerárquico tendríamos que recurrir a una duplicación de los datos en el esquema.

En el modelo de red no existen restricciones, si queremos representar que un cliente puede tener varias cuentas, cada una de las cuáles sólo puede tener un titular, y cada cuenta ésta en una sola sucursal, que por supuesto puede ser compartida por varias cuentas.
Con el modelo relacional podríamos tener ambas entidades definidas de la siguiente forma:
Cliente = (Nº Cliente: Acceso Principal; Nombre, Dirección, Nº Cuenta: Acceso Ajeno)
Cuenta = (Nº Cuenta: Acceso Principal; Saldo)

- Reflejan tan sólo la existencia de los datos sin expresar lo que se hace con ellos.
- Es independiente de las bases de datos y de los sistemas operativos (por lo que puede ser desarrollado en cualquier base de datos).
- Está abierto a la evolución del sistema.
Incluye todos los datos que se estudian sin tener en cuenta las aplicaciones que se van a tratar.
- No tienen en cuenta las restricciones de espacio y almacenamiento del sistema.
Conceptos del Modelo Entidad-Relación-
Entidades
Son objetos concretos o abstractos que presentan interés para el sistema y sobre los que se recoge información que será representada en un sistema de bases de datos. Por ejemplo, clientes, proveedores y facturas serían entidades en el entorno de una empresa.
Atributos
Es una unidad básica e indivisible de información acerca de una entidad o una relación. Por ejemplo la entidad proveedor tendrá los atributos nombre, domicilio, población, CIF.
Dominios
Es el conjunto de valores que puede tomar cada atributo. Por ejemplo el dominio del atributo población, será la relación de todas las poblaciones del ámbito de actuación de nuestra empresa.
Tablas
Es la forma de estructurar los datos en filas o registros y columnas o atributos.
Relación
Es la asociación que se efectúa entre entidades. Por ejemplo la relación entre las entidades facturas emitidas y clientes.
-
- Rectángulo- Conjunto de entidades.
- Elipse- Atributos.
- Rombos- Conjunto de relaciones
- Líneas- Unen atributos a conjuntos de entidades; unen atributos a conjuntos de relaciones; y unen conjuntos de entidades con conjuntos de relaciones. Si la flecha tiene punta, en ese sentido está el uno y si no la tiene, en ese sitio está el muchos. La orientación señala cardinalidad.
- Elípse doble- Se trata de dos elipses concéntricas. Representan atributos multivalorados.
- Elipse discontinua- Atributos derivados.
- Líneas dobles- Indican participación total de un conjunto de entidades en un conjunto de relaciones.
- Subrayado- Subraya los atributos que forman parte de la clave primaria del conjunto de entidades.

Los conjuntos de relaciones no binarias se especifican uniendo al conjunto de relaciones tantas entidades como marque la relación. No es recomendable su utilización, prefiriéndose el uso de relaciones binarias.
4.5.- Programas que conforman el DBMS
El DBMS se compone de una serie de módulos:
- El Compilador de DDL (Data Definition Language). El DDL sirve para definir estructuras de almacenamiento, y por tanto para crear esquemas conceptuales.
- El resultado de compilar todas las instrucciones DDL se va a almacenar en lo que se conoce como Diccionario de Datos. Este diccionario nos aportará información acerca de la base de datos. El diccionario de datos depende del DBMS.
- El Precompilador DML (Data Management Language). Las instrucciones de manejo que define van dentro de un lenguaje de alto nivel cualquiera ( Lenguaje Anfitrión) (El DML se llama Lenguaje Huésped). El primer paso del pre-compilador es traducir las instrucciones del DML al lenguaje anfitrión.
- El Procesador de Consultas permite al usuario "jugar" con los datos, o sea consultarlos sin necesidad de construir un programa de aplicación. Cuenta con un Optimizador de DML para optimizar esas consultas.
- El Manejador de Bases de Datos realiza la traducción entre los diferentes esquemas de la base de datos. Si un usuario quiere acceder a unos datos, el manejador comprobará su esquema externo para averiguar a que datos tiene acceso ese usuario; luego estudia el esquema conceptual completo, a continuación accede al esquema físico para saber como trabajar con ellos y finalmente los proporcionará al usuario.
4.6.- Personas relacionadas con un SBD
Administrador de base de datos (DBA)
Se encarga del diseño físico de la base de datos y de su desarrollo, gestiona el control de seguridad y concurrencia, mantiene el sistema para que siempre se encuentre operativo y se encarga de que los usuarios y las aplicaciones obtengan buenas prestaciones. El administrador debe conocer muy bien el SGBD que se esté utilizando, así como el equipo informático sobre el que esté funcionando. Más que una persona suele ser un grupo de personas.
Programador de aplicaciones
Se encargan, mediante programas en lenguajes de tercera o de cuarta generación de implementar los programas de aplicación que servirán a los usuarios finales. Estos programas de aplicación son los que permiten consultar datos, insertarlos, actualizarlos y eliminarlos.
Usuarios casuales
Son usuarios que tienen conocimientos de los DL, hacen uso de los DML de modo interactivo (es decir a través del procesador de consultas)
Usuarios ingenuos
Emplean el SBD sin conocimientos de informática, es decir usan los programas de aplicación.

4.7.- Otros tipos de bases de datos
Otros tipos de bases de datos, que no se tratarán en esta asignatura, son los conocidos como postrrelacionales:
- Modelo Orientado a Objetos
Las aplicaciones de las bases de datos en áreas como el diseño asistido por ordenador (CAD), ingeniería de software y procesamiento de documentos no se ajustan al conjunto de suposiciones que se hacen para aplicaciones habituales de procesamiento de datos. El modelo de datos orientado a objetos (BDOO) se ha propuesto para tratar algunos de estos nuevos tipos de aplicaciones, combina las mejores cualidades de los ficheros planos, bases de datos jerárquicas y relacionales. Las BDOO representan el siguiente paso en la evolución de las bases de datos para soportar el análisis, diseño y programación Orientada a Objetos.
El modelo de bases de datos orientado a objetos es una adaptación a los sistemas de bases de datos. Se basa en el concepto de encapsulamiento de datos y código que opera sobre estos en un objeto. Los objetos estructurados se agrupan en clases. El conjunto de clases esta estructurado en sub y superclases basado en una extensión del concepto ISA del modelo Entidad - Relación. Puesto que el valor de un dato en un objeto también es un objeto, es posible representar el contenido del objeto dando como resultado un objeto compuesto.
El propósito de los sistemas de bases de datos es la gestión de grandes cantidades de información. Las primeras bases de datos surgieron del desarrollo de los sistemas de gestión de archivos. Estos sistemas primero evolucionaron en bases de datos de red o en bases de datos jerárquicas y, más tarde, en bases de datos relacionales.
Estructura de objetos.
El modelo orientado a objetos se basa en encapsular código y datos en una única unidad conocida como objeto. La interfaz entre un objeto y el resto del sistema se define mediante un conjunto de mensajes.
Un objeto tiene asociado:
* Un conjunto de variables que contienen los datos del objeto. El valor de cada variable es un objeto.
* Un conjunto de mensajes a los que el objeto responde.
* Un método, que es un trozo de código para implementar cada mensaje. Un método devuelve un valor como respuesta al mensaje.
El término mensaje en un contexto orientado a objetos, no implica el uso de un mensaje físico en una red de ordenadores, si no que se refiere al paso de solicitudes entre objetos sin tener en cuenta detalles específicos de implementación.
La capacidad de modificar la definición de un objeto sin afectar al resto del sistema está considerada como una de las mayores ventajas del modelo de programación orientado a objetos.
Jerarquía de clases.
En una base de datos existen objetos que responden a los mismos mensajes, utilizan los mismos métodos y tienen variables del mismo nombre y tipo. Sería inútil definir cada uno de estos objetos por separado por lo tanto se agrupan los objetos similares para que formen una clase, a cada uno de estos objetos se le llama instancia de su clase. Todos los objetos de su clase comparten una definición común, aunque difieran en los valores asignados a las variables.
Así que básicamente las bases de datos orientados a objetos tienen la finalidad de agrupar aquellos elementos que sean semejantes en las entidades para formar un clase, dejando por separado aquellas que no lo son en otra clase.
Por ejemplo: Retomemos la relación alumno-cursa-materia agregándole la entidad profesor; donde los atributos considerados para cada uno son alumno: Nombre, Dirección, Teléfono, Especialidad, Semestre, Grupo; profesor: Nombre, Dirección, Teléfono, Número económico, Plaza, RFC; Materia: Nombre, Créditos, Clave.
Los atributos de nombre, dirección y teléfono se repiten en la entidad alumno y profesor, así que podemos agrupar estos elementos para formar la clase Persona con dichos campos. Quedando por separado en alumno: Especialidad, semestre, Grupo. Y en profesor : Número económico, Plaza y RFC; la materia no entra en la agrupación (Clase persona) ya que la clase específica los datos de solo personas, así que queda como clase materia.
Herencia.
Las clases en un sistema orientado a objetos se representan en forma jerárquica como en el diagrama anterior, así que las propiedades o características del elemento persona las contendrán (heredaran) los elementos alumno y profesor. Decimos que tanto la entidad Alumno y profesor son subclases de la clase persona este concepto es similar al utilizado en la de especialización (la relación ISA) del modelo E-R.
Se pueden crear muchas agrupaciones (clases) para simplificar un modelo así que una jerarquía (en forma gráfica) puede quedar muy extensa, en estos casos tenemos que tener bien delimitados los elementos que intervienen en una clase y aquellos objetos que las heredan.
Consultas orientadas a objetos:
Los lenguajes de programación orientados a objetos requieren que toda la interacción con objetos se realiza mediante el envío de mensajes.
Consideremos el ejemplo de alumno-cursa-materia deseamos realizar la consulta de los alumnos que cursan la materia de Base de Datos 1, para realizar esta consulta se tendría que enviar un mensaje a cada instancia alumno.
Así un lenguaje de consultas para un sistema de bases de datos orientado a objetos debe incluir tanto el modelo de pasar el mensaje de objeto a objeto como el modelo de pasar el mensaje de conjunto en conjunto.
Complejidad de Modificación.
En base de datos orientados a objetos pueden existir los siguientes cambios:
* Adición de una nueva clase: Para realizar este proceso, la nueva clase debe colocarse en la jerarquía de clase o subclase cuidando las variables o métodos de herencia correspondientes.
* Eliminación de una clase: Se requiere la realización de varias operaciones, se debe de cuidar los elementos que se han heredado de esa clase a otras y reestructurar la jerarquía.
En sí la estructuración de modelos orientados a objetos simplifica una estructura evitando elementos o variables repetidas en diversas entidades, sin embargo el precio de esto es dedicarle un minucioso cuidado a las relaciones entre las clases cuando en modelo es complejo, la dificultad del manejo de objetos radica en la complejidad de las modificaciones y eliminaciones de clases, ya que de tener variables que heredan otros objetos se tiene que realizar una reestructuración que involucra una serie de pasos complejos.
Como ejemplo de desarrollo, se describen primeramente los tipos de objetos importantes del dominio de aquellos tipos de objetos. Estos tipos de objetos determinan las clases que conformarán la definición de la BDOO. En un caso real, se supone una base de datos diseñada para almacenar la geometría de ciertas partes mecánicas incluiría las clases CILINDRO, ESFERA Y CUBO. El comportamiento de CILINDRO podría incluir información relativa a sus dimensiones, volumen área superficial:
Clase de CILINDRO{
ALTURA FLOTANTE ();
RADIO FLOTANTE ();
VOLUMEN FLOTANTE ();
AREA DE SUPERFICIE FLOTANTE ();
};
Se puede llegar a definiciones similares para el cubo y la esfera. En la definición anterior, ALTURA,RADIO y ÁREA representan los mensajes que se pueden enviar a un objeto CILINDRO.
La Implantación se lleva a cabo en el mismo lenguaje, escribiendo funciones correspondientes a las solicitudes OO:
CILINDRO::ALTURA () {RETORNA CILINDRO_ALTURA;}
CILINDRO::VOLUMEN () {RETORNA PI*RADIO ()*ALTURA ();}
En este caso, la Altura se almacena como un elemento de los datos, mientras que volume se calcula mediante la fórmula apropiada. Observe que la implantación interna de volume utiliza solicitudes para obtener altura y radio. Sin embargo, el aspecto más importante es la sencillez y uniformidad que experimentan los usuarios de CILINDRO. Sólo necesitan conocer la forma de enviar una solicitud y las solicitudes disponibles.
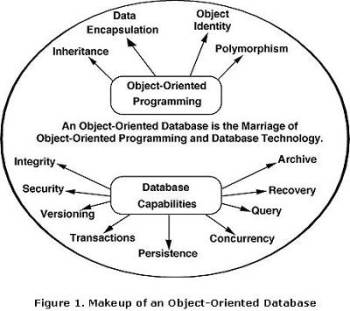
- Modelo Semántico
Tienen como objetivo describir de un modo más preciso la información contenida en la base de datos.
- Modelo Deductivo
Son capaces de deducir hechos a partir de las relaciones base y una serie de axiomas deductivas o reglas de inferencia.
- No tienen en cuenta las restricciones de espacio y almacenamiento del sistema.
Organizaciones:
Agencia Española de Protección de Datos.
http://www.agpd.es



Aquí puedes cambiar el tamaño y color del texto
Agrégame en tus círculos

TUTORÍAS
Rafael Barzanallana
Escepticismo, ciencia, informática, ...
Escepticismo en España
Escepticismo en América
TUTORÍAS
